# 云胡的编程周报第 016 期
时间:2023/11/27-2023/12/10
# 一、点滴记录
# 1
给 Vue3 项目配置不同环境
在项目主目录下新建 .env.development 和 .env.production 文件,分别表示开发环境和正式环境。
.env.development中填入
NODE_ENV=development
# 开发环境的后端地址
VUE_APP_API_BASE_URL=http://localhost:8090/
2
3
4
.env.production 中填入
NODE_ENV=production
# 正式环境的后端地址,正式环境使用了 nginx,所以要加上 api
VUE_APP_API_BASE_URL=https://library.yunhu.wiki/api/
2
3
4
在封装 axios 那边更改 baseURL
// 创建 axios 请求实例
const serviceAxios = axios.create({
baseURL: process.env.VUE_APP_API_BASE_URL,
timeout: 10000,
// 跨域请求是否需要携带 cookie
withCredentials: false,
});
2
3
4
5
6
7
这时候开发和正式打包会分开,就不会出现打包正式环境的时候,后端地址忘了改从而请求失败。
# 2
列出所有已创建的 Conda 环境
conda info --envs
# 3
Linux服务器出现:
welcome to emergency mode!after logging in ,type “journalctl -xb” to view system logs,“systemctl reboot” to reboot ,
“systemctl default” to try again to boot into default mode。
2
一些误操作进入了紧急模式,先登录到系统里,然后编辑 /etc/fstab这个文件,这个是开机挂载的,将无关的注释掉,然后重启即可。
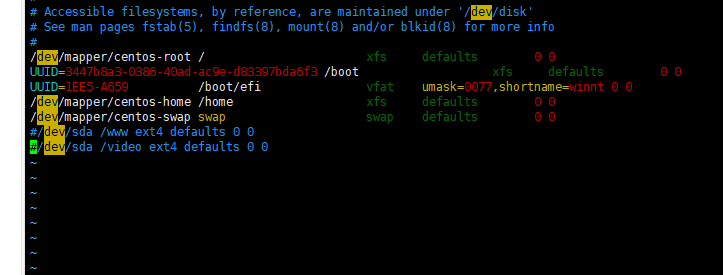
# 4
在用 pip 安装包的时候发现没有磁盘空间了,使用 sudo df -h 查看所有文件系统的使用情况,发现服务器给 root文件系统设置了 50G,已经用满了。
使用 find / -xdev -type f -size +1000M 命令查找大于 1000M的文件。
/表示搜索的路径-xdev表示在当前文件系统下搜索-type f表示只搜索文件,而不是目录。-size +1000M表示搜索大小大于1000MB的文件。
搜索后发现很多 mysql 的 binlog 文件,删除即可。
# 5
使用 gunicorn运行 flask 后端时,由于 flask 跑目标检测项目耗时的时间较长,会出现超时,因此需要自定义超时时间。
gunicorn your_app:app --timeout 60
这边实例是 60s,可以自行设置超时时间。
# 6
Linux 中使用 df -hl 查看所有文件系统的占用情况,我的腾讯云服务器如下:
Filesystem Size Used Avail Use% Mounted on
devtmpfs 4.0M 0 4.0M 0% /dev
tmpfs 986M 24K 986M 1% /dev/shm
tmpfs 395M 584K 394M 1% /run
tmpfs 5.0M 0 5.0M 0% /run/lock
/dev/vda1 40G 17G 21G 45% /
overlay 40G 17G 21G 45% /var/lib/docker/overlay2/096180e590d9e2c3a4756338bab8c259c2e79d683301e6971238d0c2985a89f5/merged
tmpfs 198M 0 198M 0% /run/user/0
2
3
4
5
6
7
8
9
根文件系统只有 40G,已经用了 17G 了。
# 7
直接在 IDEA 中使用 mvn install 安装本地 jar 包会出错,换成在 cmd 中安装就可以,不知道是不是权限问题,先记录。
# 8
Linux 使用 ll -h 友好查看底下的文件和子目录大小等情况。
# 9
Linux 服务器访问局域网另外一台服务器路径。
假设局域网 192.168.1.10 这台服务器要访问 192.168.1.20 这台服务器上的文件夹.。
首先在 192.168.1.20 上安装 Samba 服务,命令如下
sudo yum install samba
安装完毕后,在 /etc/samba/smb.conf配置文件中,配置共享文件夹。
[share_folder]
path = /path/to/shared/folder
read only = no
guest ok = yes
2
3
4
注意 share_folder是后面 192.168.1.10 要设置的路径,我一直以为是 path 里面的,反复都弄不成,
share_folder 和 path 都可以按照你的要求自定义。
配置好后,使用testparm 检查配置文件语法是否正确。
然后再设置密码 Samba 账号密码
sudo smbpasswd -a your_username
输入两次密码即可。 改完之后重新载入配置。
sudo systemctl restart smb
192.168.1.20 服务器就设置好了。
现在开始在192.168.1.10 服务器上设置
CIFS 是一种网络文件共享协议,需要先安装它的客户端 cifs-utils。
sudo yum install cifs-utils
然后进行挂载
sudo mount -t cifs //remote_ip_address/share_folder share_folder -o username=your_username,password=your_password
remote_ip_address: 远程计算机的 IP 地址。
share_folder: 共享的文件夹名称。
your_username: 远程计算机的用户名。
your_password: 远程计算机的密码。
# 二、发现
# 1
labelImg
https://github.com/HumanSignal/labelImg (opens new window)
深度学习中标记图像的目标区域,可以生成 VOC 格式的数据集。
# 2
gpt-crawler
https://github.com/BuilderIO/gpt-crawler (opens new window)
可以爬取互联网上的数据,生成 json 文件,导入到 OpenAi 的 Assistant 中就可以让 LLM 模型来加载,拥有自己的知识库,之后可以根据爬到的数据提问,
# 三、后记
这两周懈怠了,和朋友聊天聊的太开心了,没有花精力总结了,一周没更新,罪过罪过。